Convolution
CNN 也是 ANN 的一种,特点是它可以发现 pattern。
CNN 不光有基本的网络层,还有更重要的卷积层。
卷积层对数据的变换操作称为 convolution operation。
在数学上,由卷积层执行的卷积运算称为互相关 cross-correlations。
卷积层的操作
开始阶段,通过 filter 进行 pattern 发现。
patterns
在一个图形中,pattern 可以是形状,材质 textures,物体 objects。
一个可以发现形状的 filter 可以称为
edge detector往后,filter 更复杂,不是简单的边缘和多边形,而是发现特殊的物体,例如眼睛,耳朵,头发,羽毛等。
更深的网络层可以发现更复杂的物体,例如狗,鸟等。
通过例子看一下操作
手写数字识别

假设第一个层就是卷积层,这时需要指定 filter 的数量,
filter 的数量决定了输出 channel 的数量。
从技术上讲,filter 可以认为是一个相对较小的矩阵(张量),为此,我们需要决定该矩阵具有的行数和列数,并使用随机数初始化该矩阵中的值。
卷积层
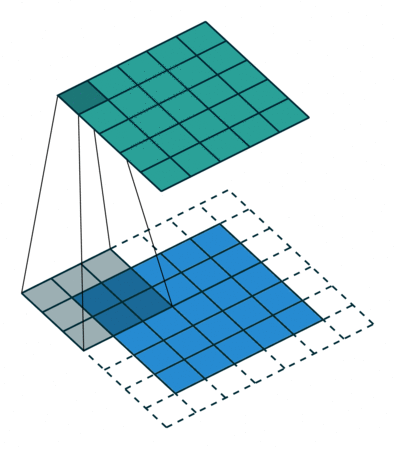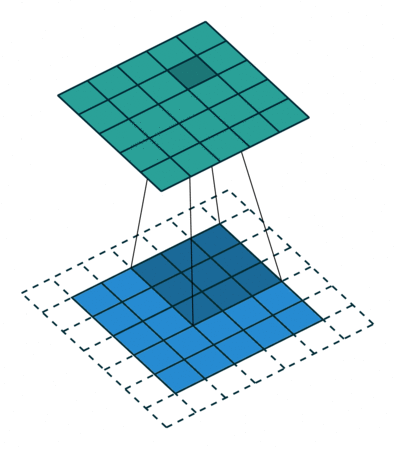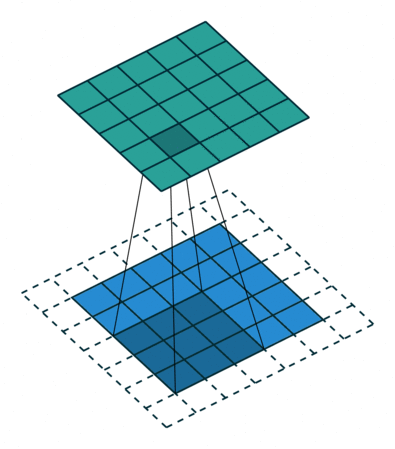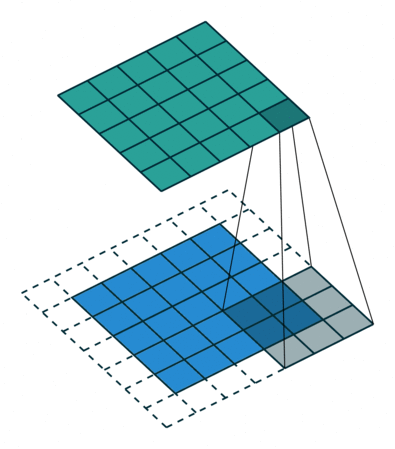
蓝色是输入 channel,绿色是输出 channel,中间的不断滑动的四条直线表示 3x3 的 convolutional filter。
可以看到,输入 channel 到输出 channel 的元素数量没变,只是都经过 flter 处理了一下
卷积运算 Convolution operaton
滑动操作就是卷,准确地说,这个 filter 正在把输入的每个 3x3 的块进行卷积。
蓝色输入 channel 是来自 MNIST 数据集的图像的矩阵表示。
该矩阵中的值是图像中的各个像素。
这些图像是灰度图像,每个像素可以用 0-255 中一个整数值表示,因此我们只有一个输入 channel。
RGB 图像有 3 个颜色通道。
我们将 filter 与前 3 x 3 像素块点积(按元素乘积的总和。或者说 Frobenius Inner product 或 Hadamard product 的和),然后将结果存储在输出 channel 中。
然后,change 滑动到下一个 3 x 3 块,计算点积,并将该值存储为输出 channel 中的下一个像素。
整个输出 channel 称为 feature map。
这只是一个非常简单的示例,但是正如前面提到的,我们可以将这些 filters 视为模式发现器。
实例
一个 MNIST 的图片

假设我们的卷积层有 4 个 filter,这些值可以通过使 - 1 对应于黑色,1 对应于白色,0 对应于灰色来直观地表示。

如果我们将原始的七个图像分别与这四个 filter 中的每个进行卷积,则每个 filter 的输出如下所示:

我们可以看到所有这四个 filter 都在检测(detect)边缘。
在输出通道中,最亮的像素可以解释为 filter 检测到的结果像素。
第一个中,我们可以看到数 7 的顶部的水平边缘,并以最亮的像素(白色)表示。
第二个检测左垂直边缘,再次以最亮的像素显示。
第三个检测底部水平边缘.
第四个检测右侧垂直边缘。
这些是我们在卷积神经网络开始时可能会看到的过滤器。
更复杂的过滤器将位于网络的更深处,并将逐渐能够检测到更复杂的模式,如下所示:

还有更更复杂的

最神奇的是这些 pattern filter 是通过网络自动导出的
filter 的值以随机值开始,并且随着网络在训练期间学习而改变。
filter 的模式检测功能会自动出现。
过去,计算机视觉专家会手动开发 filter(模式检测器)。
一个示例是边缘检测器 Sobel filter。
但是,通过深度学习,我们可以使用神经网络自动学习这些过滤器!
总结自 https://deeplizard.com/learn/video/YRhxdVk_sIs
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论。