输入一个链表,反转链表后,输出新链表的表头。
从大一就开始学,学了忘,忘了学。。。
所有代码为 JavaScript 代码,牛客上运行通过。
迭代
function reverseList(Node head) {
let prev = null;
let curr = head;
while (curr) {
let next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev;
}prev 保存前一个节点(可以想象为虚的 val 无意义额定头结点,它的 next 指向链表第一个节点,这样好理解),curr 为当前要反转的节点,next 为后面的节点(下一次循环去反转的节点)。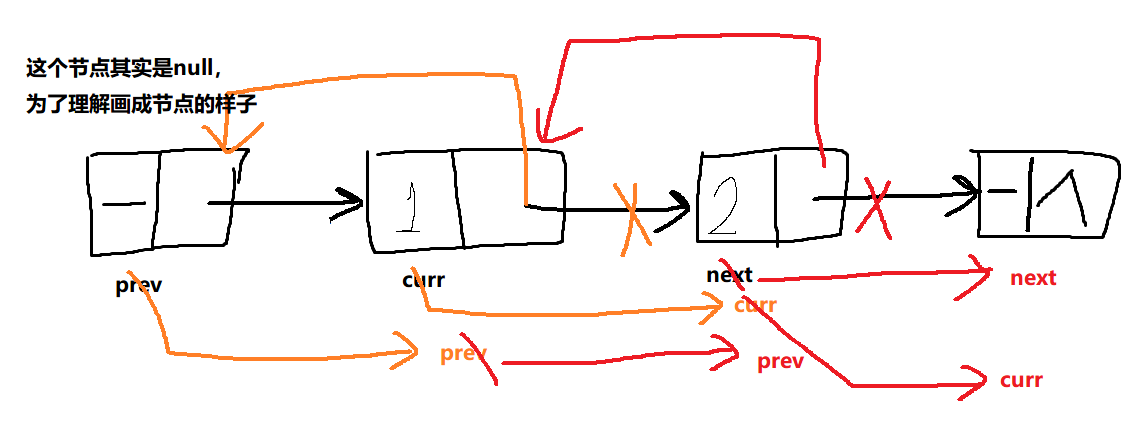
橙色和红色表示第一次,第二次循环。
- 时间复杂度显然是链表长度 N
- 空间复杂度只用了两个额外的遍历,故为 O(1)
递归
我可以看懂的伪递归:
function ReverseList(head)
{
function reverse(prev, curr) {
if (curr === null) {
return prev;
}
let next = curr.next;
curr.next = prev;
return reverse(curr, next);
}
return reverse(null, head);
}其实就是把迭代的变量用函数的参数保存了。所以说是 “伪递归”。
由于是在 return 中直接调用函数,所以是尾调用。
又因为尾调用函数是自身,所以是尾递归。。。
调用及尾递归可以参考 阮一峰大佬的博客
- 时间复杂度:递归执行 N 次,故 O(N)
- 空间复杂度:递归执行 N 次,每次都要保存几个变量,O(mN),m 为变量个数,故为 O(N),尾递归优化后可能会降低空间复杂度。
看不懂的递归:
function ReverseList(head)
{
if (head === null || head.next === null) {
return head;
}
let p = ReverseList(head.next);
head.next.next = head;
head.next = null;
return p;
}一段大佬的解释:
关键就是理解
p是反转后链表的表头,也就是原链表的最后一个节点。注意到从第一行的语句返回head之后,在以后的函数出栈过程中返回值p一直没有变,只是将当前函数的输入结点进行反转,就可以理解这个递归的过程了。
一个运行过程模拟图:
为什么 head === null || head.next === null 而不是只写一个判断 head === null 或者 head.next === null???
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论。